Section 2: Discussion & Topic Research
Software Design Patterns
Software design patterns are standardised patterns, reusable solutions to general programming problems. They offer a framework of structure in organizing code, improve maintainability,
improve scalability, and improve redundancy. Patterns can also help to enhance better collaboration because they provide a common language of software architecture which enables the developers to create systems that are not only modular but also extendible. The design patterns were well adopted in this project in order to isolate the concerns and favour bstraction in functionality. They took the key role in organizing the interaction between the algorithms and the user interface, enhancing the reusability of the code and making it easier to make changes in the future. The use of every pattern was made to meet the needs of particular components.
| Algorithm | Pattern | Type | Reason for Use |
| Text Editor | Strategy | Behavioral | Allows dynamic switching between formatting behaviors |
| Shape Factory | Factory Method |
Creational | Encapsulates object creation logic for extensibility |
| Printer Adapter |
Adapter | Structural | Bridges incompatible interface for legacy compatibility |
Table 1: Design Patterns Implemented
The practical advantages of these applications were attainment of easier debugging, enhanced readability and role segregation in the system. These design patterns ensured a sturdy base on which to put in complex logic into an easy to use GUI as well as ensuring system modularity.
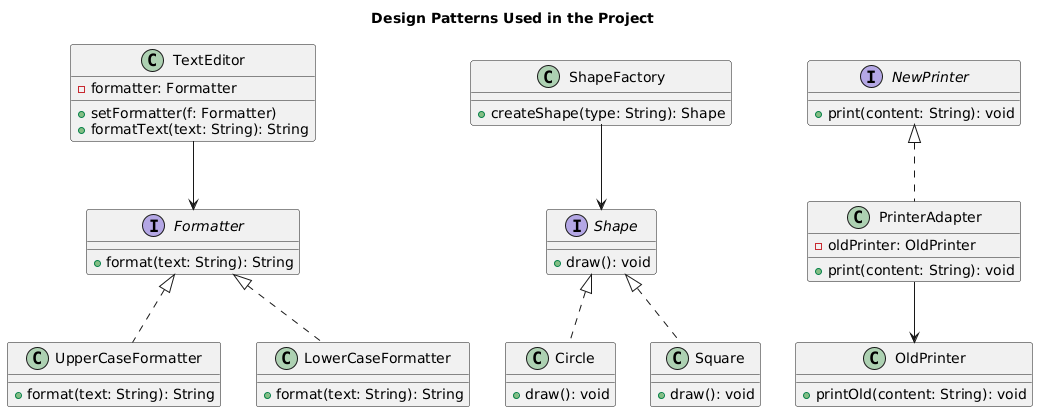
Figure 1: Implementation of Strategy
Time Complexity & Big O Notation
Time complexity is a theoretical metric explained as the efficiency of an algorithm, that is, how the time taken to run the algorithm varies depending on the input size. Big O notation is used to offer a standard expression of this growth eliminating factors specific to machines (Yaser Ali Enaya, Karim and Bilal, 2025). An example is that O(n) increases with the input size linearly, whereas O(n²) increases and is therefore much slower for very large input. On the other hand, the growth rate of O(log n) algorithms is logarithmic thus making them effective even with big data.
The time complexity was best experienced in the sorting algorithms in this project. Selection Sort has the same complexity O(n²) as Bubble Sort, which is why both methods are inefficient with large datasets as they both have nested iterations (Mohsen Mohammadagha, 2025). One can however use them to illustrate brute-force and iterative logic because of their simplicity and predictability. Conversely, Merge Sort has adopted a divide-and-conquer approach and demonstrates performance of O(n log n), with stable and effective performance that still gives consistent and efficient outcomes irrespective of input size.
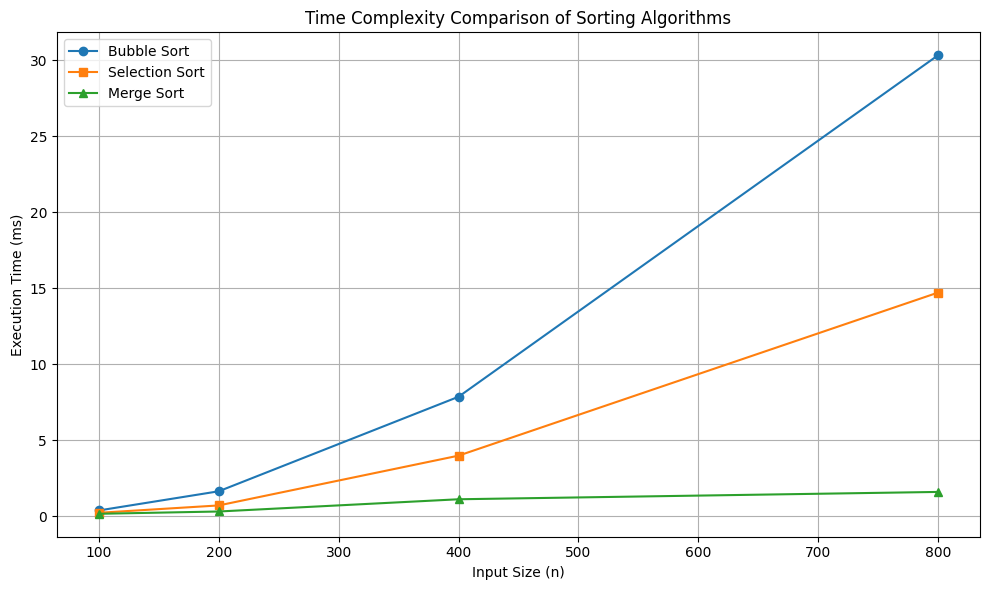
Figure 2: Time Complexity Comparison
Selection Sort was thus given more preference in performance-intensive situations. Its better scalability was a reason to be included as the recommended form of sorting. Presentation of difference in algorithmic thinking and computational trade-offs was created by the use of Selection and Bubble Sort (Li, 2024).
Browse all assignment subjects to find guidance on algorithms, software design, and project reports.
Software Development Practices
Developing software effectively not only involves capable code but also a well-organized and ordered practice in terms of quality and maintainability as well as teamwork (Xu and Zhang, 2021). The following project aims have been designed in a manner that is directed towards a modular approach, test coverage and version control.
GitHub was the version control tool used that allowed progressive development, backups, and team development in the future (Mariot Tsitoara, 2020). The repository also had a good commit history and a folder structure in order to aid traceability. Besides, the GitHub Code of Conduct agreement was also recognized and followed, which demonstrates readiness toward professional standards and value formation.
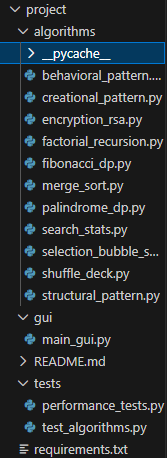
Figure 3: Modular Folder Structure of the Project
There was a strong testing policy that was observed with the help of Python's unittest. Functional tests were used to confirm that all algorithm outputs were correct and performance tests were used to measure the performance of the algorithm with respect to the input size. Special occurrences like empty inputs, duplicate values, and huge arrays were particularly tested to ensure reliability and scalability.
The GUI code was separated into a gui/ folder whereas all the testing logic was located in the tests/ directory. This division of responsibility increased code clarity and made maintenance easier. The GUI developed using Tkinter was smooth to use, allowing dynamic user input, switching between ascending and descending sort order, and providing clear real-time feedback. The GUI converted complex algorithmic logic into a user-friendly front-end, making the system easy to use and interactive.
Eventually, this resulted in a clean and professional software product that supports contemporary development standards.
Algorithm Design & Thinking
Each algorithm in the project was thoroughly planned before its implementation taking into consideration the input requirement, the computational complexity and what was anticipated in the interaction of each algorithm as per the graphical interface. The design stage was aimed at creating a balance between performance, user experience and edification making sense.
Algorithms were chosen not only in terms of their technical value, but also in terms of the pedagogical potential. An example that clearly demonstrates the application of dynamic programming is the calculation of Fibonacci number by memorization to prevent the identical recursive executive calls and to have the optimal time performance of O(n) (Habib Izadkhah, 2022). RSA encryption algorithm also employed Miller-Rabin primality test to efficiently produce prime numbers of significant size, and that reveals the use of probabilistic methods in cryptography.
In the case of statistical search algorithm, application-specific logic was written to calculate the mode, median, and quartiles using the user-typed data with no reference to any other library. This involved careful sorting and frequency counting and median rules of even and odd data. To randomize a standard 52-card deck in a uniformly randomized manner, the deck shuffling algorithm used the Fisher-Yates algorithm, which was written as a special-purpose randomizer.
All the design decisions in the project were made with regard to efficient control flow and correct data structure. Where applicable, arrays, dictionaries and tuples were resorted to in order to make clarity and speed. The GUI interface was reinforced with input validation and error handling and logical grouping of member features of the algorithms in interactive tabs. This strategy optimized the user experience, as well as made it resistant to various input sources.
Section 3: Reflection
Reflection Framework: "What? So What? Now What?"
What?
In this project, there was the creation of a complete portfolio of algorithms, with eleven fundamental algorithm implementation as well as three different software design patterns. The whole solution is created in Python, and the only algorithm libraries in any form were never used, which in turn supports the original logic behind every implementation (Ahmed Fawzy Gad, 2023). The entire functionality was woven into a user interface through Tkinter that was to offer user-friendly points of contacts on how inputs and outputs are to be handled. To identify and verify the correctness and scalability, the dual-layer testing strategy has been used including the run-time analysis where functional tests through the unittest module and performance benchmarking were conducted. Modularity and maintainability, which were mandated by professional software development, were also implemented by the project structure.
So What?
This experience was a great addition to the insight into the contribution of design patterns to the creation of modular and extensible codebases. Separating formatting logic via Strategy pattern, object creation via Factory Method and interface via Adapter pattern was a chance to see how design patterns can resolve real-life structural and behavioural issues in software systems. The testing was critical in unearthing edge cases, for example recursion limits of factorial functions and sort stability. It also strengthened the need of verifying the expected and boundary inputs. There was another layer of complexity brought in by the requirement to integrate GUI, thus exposing the need to provide strong error handling and real-time feedback systems to make it usable. In addition, the direct observation of the algorithm efficiency and its impact on the GUI responsiveness gave practical knowledge of the real-world significance of time complexity.
Get expert Computer Science assignment help for Python projects, GUI development, and algorithm analysis.
Now What?
In the future, more advanced design patterns are evidently tempting to be adopted such as Observer, to decouple event-driven systems, and Builder, to support the creation of complex objects. The project also highlighted the usefulness of automated testing pipelines. The introduction of Continuous Integration (CI) in the form of GitHub Actions or pytest in further iterations would help maintain code quality (Eero Kauhanen et al., 2021). The user interface may also be improved with better layout design, adaptable input fields, and accessibility features. In addition, the application of Python type hints along with clean architecture concepts would enhance code understanding and minimize runtime errors. In general, the given project provided both technical and conceptual groundwork, which preconditioned further investigation into scalable, maintainable, and user-oriented software development practices.
References
-
Ahmed Fawzy Gad (2023). PyGAD: an intuitive genetic algorithm Python library. Multimedia Tools and Applications. doi: https://doi.org/10.1007/s11042-023-17167-y .
-
Eero Kauhanen, Nurminen, J.K., Mikkonen, T. and Matvei Pashkovskiy (2021). Regression Test Selection Tool for Python in Continuous Integration Process. 2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). doi: https://doi.org/10.1109/saner50967.2021.00077 .
-
Habib Izadkhah (2022). Dynamic Programming. pp. 401-424. doi: https://doi.org/10.1007/978-3-031-17043-0_11 .
-
Li, M. (2024). Balancing Performance Trade-offs in Modern Sorting Methodologies. Advances in Engineering Technology Research, 9(1), p. 588. doi: https://doi.org/10.56028/aetr.9.1.588.2024 .
-
Mariot Tsitoara (2020). Beginning Git and GitHub: a comprehensive guide to version control, project management, and teamwork for the new developer . New York, NY: Apress.
-
Mohsen Mohammadagha (2025). Hybridization and Optimization Modeling, Analysis, and Comparative Study of Sorting Algorithms: Adaptive Techniques, Parallelization, for Mergesort, Heapsort, Quicksort, Insertion Sort, Selection Sort, and Bubble Sort . [online]. doi: https://doi.org/10.31224/4537 .
-
Xu, Z. and Zhang, J. (2021). Algorithmic Thinking. Computational Thinking: A Perspective on Computer Science, pp. 131-182. doi: https://doi.org/10.1007/978-981-16-3848-0_4 .
-
Yaser Ali Enaya, Karim, A.A. and Bilal, G.A. (2025). Stealing Some Notation from Big O Notation to Develop a New Multithreading Priority Formula . ITEGAM - Journal of Engineering and Technology for Industrial Applications (ITEGAM-JETIA), 11(51). doi: https://doi.org/10.5935/jetia.v11i51.1505 .

UPTO55%
Avail The Benefit Today!
To View this & another 50000+ free